Scaling RL to Non-Verifiable Domains Through Symbolic Abstractions
RLSAF: Reinforcement Learning from Symbolic Abstraction Feedback
Reinforcement Learning (RL) has had its “superhuman” moments in fields like Chess, Go, and more recently, Coding and Mathematics. What do these have in common? In these fields, we have clear ground truth: a compiler either runs the code or it doesn’t; a math answer based on expert-written step-by-step explanations is either correct or it’s not. But the real world isn’t always that binary.
🔍 Key Challenge: As Jeff Dean (Chief Scientist, Google DeepMind and Google Research) recently pointed out, one of the biggest open problems in AI right now is how to scale RL to “non-verifiable” domains like law, medicine, or finance, where there is no simple “compiler” to verify the model’s output. Existing approaches use (variants of) RLHF/RLAIF (human/AI feedback), which is not verifiable and is itself bottlenecked by the performance of underlying LLMs.
This is where the “Verifiability Gap” lives, and it’s what we set out to solve.
The Bridge: Symbolic Abstractions
To bridge this gap, we need a way to provide models with a rich, verifiable reward signal without requiring a human to manually grade every single response. Our solution is to use Symbolic Abstractions. I call this framework RLSAF: Reinforcement Learning from Symbolic Abstraction Feedback.
💡 The Core Idea: While natural language is messy and ambiguous, the underlying logic of a professional domain is often structured. By representing a domain’s axioms and rules through a Symbolic Abstraction, we can create an “implicit reward model.” This abstraction acts as a source of truth that the model can use to check its own reasoning during the RL process, without needing a human in the loop for every step.
From Abstraction to Reward: Using Medicine as a Testbed
In our newly released paper, we used Knowledge Graphs (KGs) as our symbolic abstraction of choice. Think of a Knowledge Graph as a “map of truth” for a specific field — or more precisely, as an implicit reward model, where verified paths between nodes encode the axiomatic reasoning steps a model must learn to compose and solve new problems. In medicine, for example, a KG isn’t just a database; it’s a map of verified relationships between symptoms, pathologies, and treatments. This structure allows us to move beyond simple outcomes and look at the reasoning path itself. We show how a Medical Knowledge Graph provides a high-quality, verifiable reward signal during RL training.
By using the KG to derive reward signals, we moved beyond “outcome-based” rewards (did the model guess the right disease?) to “process-based” rewards (did the model follow the correct biological path to get there?).

✨ By design, such a reward is:
- Scalable: It doesn’t require humans in the loop.
- Grounded: It is tied to the actual principles of the domain.
- Transparent: You can see exactly which “triples” or axioms the model needs to successfully navigate the problem.
Evidence of Scaling
We didn’t just want to see if this worked; we wanted to see if it scaled. We began our experiments on an 8B model and, after seeing a strong upward trend, scaled the approach to a 14B model.
The results were striking. Our 14B model, trained through RLSAF, began to demonstrate compositional reasoning. It could solve 4- and 5-hop reasoning tasks despite only being trained on simpler 1-3 hop tasks. It wasn’t just memorizing; it was learning to “think” through the abstraction.
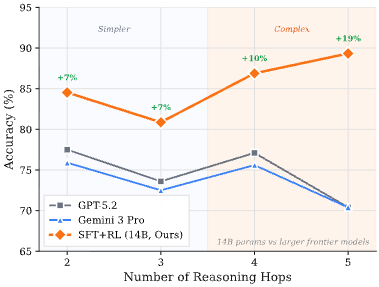
🏆 Key Result: Our model didn’t just compete; it surpassed much larger frontier models like Gemini 3 Pro and GPT-5.2 on the most difficult reasoning tasks. This suggests that a smaller model with a “structured logic rail” can outperform a massive model relying on brute-force scale.
The Path Forward: A Universal Framework for Alignment
While our paper focuses on medicine, the implications of RLSAF are much broader. We view medicine as the ultimate “stress test” for this approach, but the goal is for the community to take this approach and verify it across every complex, seemingly intractable human domain.
Why stop at medicine? The beauty of symbolic abstractions is that they exist everywhere:
- Law & Policy: Using legal ontologies and case-law graphs to perform verifiable legal reasoning.
- Finance: Leveraging market structures and regulatory frameworks as abstractions for risk assessment.
- Robotics: Using Scene Graphs to give models a symbolic understanding of physical space.
- Scientific Discovery: Using formal logic and chemical property graphs to guide RL in drug discovery or materials science.
🚀 Why This Matters: I truly believe this idea has “legs to stand on” because it solves the scalability problem of RLHF. We cannot hire 100,000 doctors or lawyers to sit and grade model outputs 24/7. But we can exploit the structured knowledge humanity has already built — the symbolic abstractions — to perform verifiable RL end-to-end.
Join the Research
Our paper is a proof-of-concept that symbolic feedback can lead to truly intelligent systems that reason from first principles. We want the community to adopt this, break it, and improve it in other domains.
If you’re working on alignment, KG-augmented RL, or reasoning in “messy” domains, let’s talk. The preprint is available here: https://arxiv.org/abs/2601.15160.
I’d love to hear your thoughts on where else RLSAF could be applied. Which domain should we tackle next? Feel free to get in touch at yuvalkansal@princeton.edu
Enjoy Reading This Article?
Here are some more articles you might like to read next: